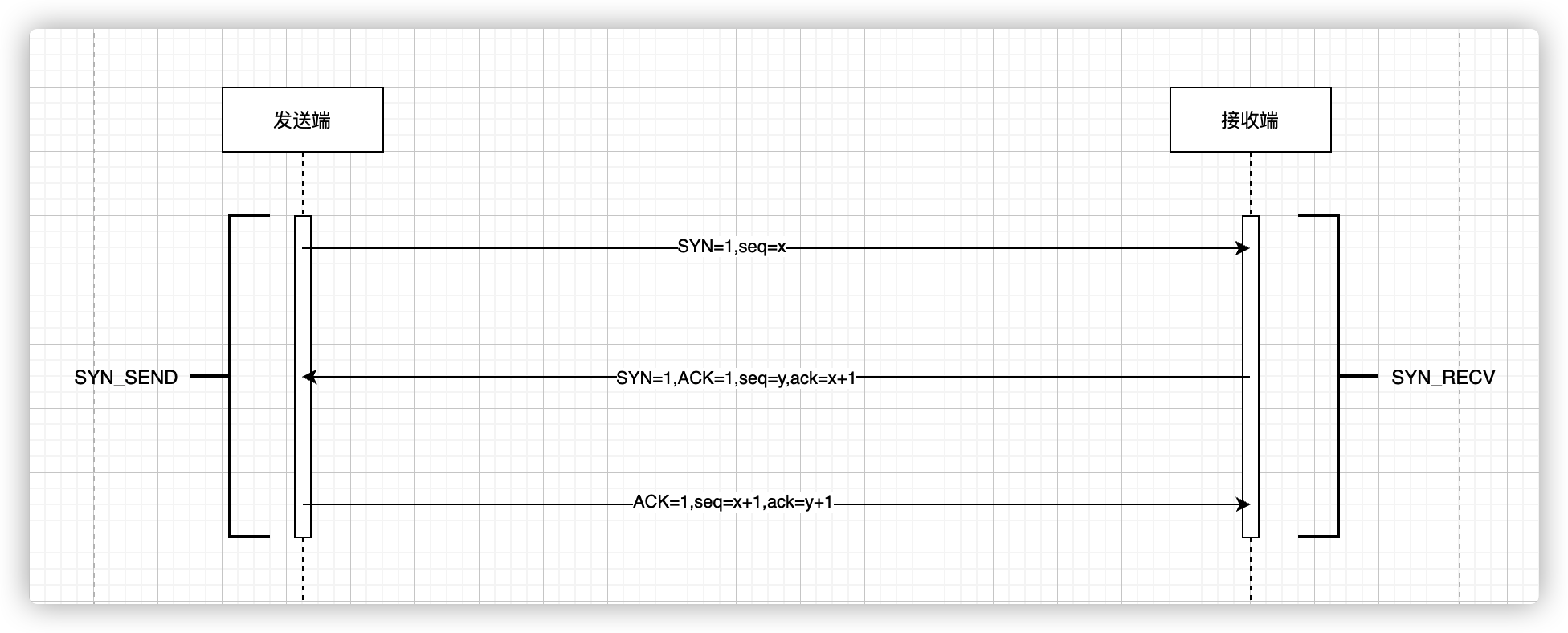
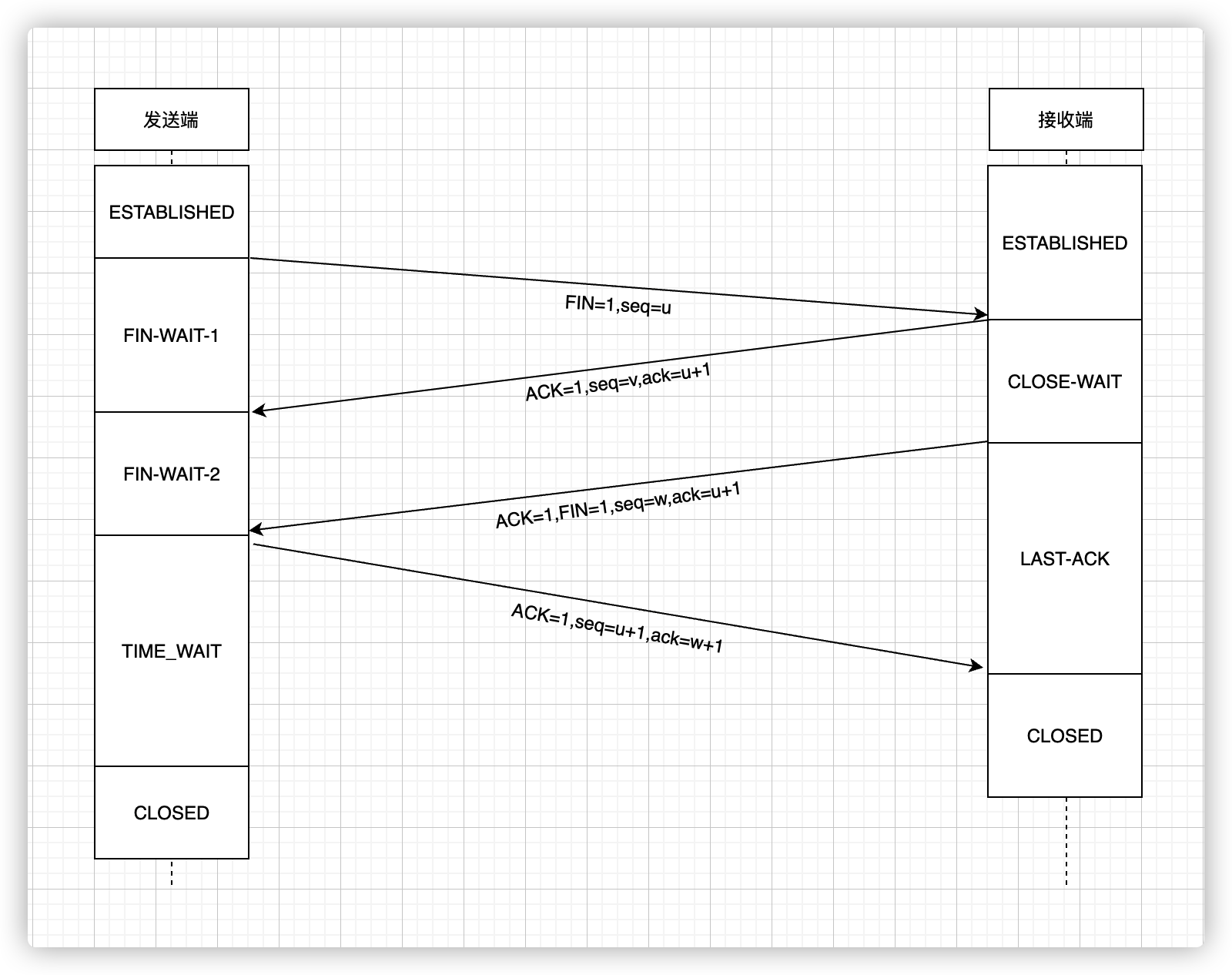
网络编程 TCP/IP 协议 TCP/IP 协议的基本概念 TCP/IP 协议不是 TCP 和 IP 这两个协议的合称,而是指因特网整个 TCP/IP 协议族。
TCP/IP 是 Transmission Control Protocol / Internet Protocol 的简写,即 ‘传输控制协议/因特网互联协议’,又名网络通讯协议,是 Internet 最基本的协议、Internet 国际互联网络的基础。
TCP/IP 由网络层的 IP 协议和传输层的 TCP 协议组成。
TCP/IP 定义了电子设备如何连如因特网,以及数据如何在它们之间传输的标准。协议采用了4层的层级架构,每一层都呼叫它的下一层所提供的协议来完成自己的需求。通俗而言,TCP 负责发现传输的问题,一旦发现问题就发出信号,要求重新传输,直到所有数据正确地传输到目的地。而 IP 是给因特网每一台联网设备规定一个地址。
参考模型 TCP/IP 参考模型 TCP/IP 参考模型是首先由 ARPANET 所使用的网络体系结构。这个体系结构在它的两个主要协议出现以后被称为 TCP/IP 参考模型。这一网络协议共分为四层:
网络访问层,即 Network Access Layer,在 TCP/IP 参考模型中并没有信息描述,只是指出主机必须使用某种协议与网络相连。
互联网层,即 Internet Layer,是整个体系结构的关键部分,其功能是使主机可以把分组发往任何网络,并使分组独立地传向目标。这些分组可能是经过不同的网络,到达的顺序和发送的顺序也可能不同。高层如果需要顺序收发,那就必须自行处理对分组的排序。互联网层使用因特网协议(IP, Internet Protocol)。
传输层,即 Transport Layer,使源端和目的端机器上的对等实体可以进行会话。在这一层定义了两个端到端的协议:传输控制协议(TCP,Transmission Control Protocol)和用户数据报协议(UDP,User Datagram Protocol)。
TCP 是面向连接的协议,它提供可靠的报文传输和对上层应用的连接服务。为此,除了基本的数据传输外,它还有可靠性保证、流量控制、多路复用、优先权和安全性控制等功能。
UDP 是面向无连接 的不可靠传输协议,主要用于不需要 TCP 的排序和流量控制等功能的应用程序。
应用层,即 Application Layer,包含所有的高层协议,包括:虚拟终端协议(TELNET, TELecommunications NETwork)、文件传输协议(FPT, File Transfer Protocol)、电子邮件传输协议(SMTP, Simple Mail Transfer Protocol)、域名服务(DNS, Domain Name Service)、网上新闻传输协议(NNTP, Net News Transfer Protocol)和超文本传输协议(HTTP, HyperText Transfer Protocol)。
TELNET 允许一台机器上的用户登录到远程机器上,并进行工作。
FTP 提供了有效地将文件从一台机器上转移到另一台机器上的方法。
SMTP 用于电子邮件的收发。
DNS 用于把主机名映射到网络地址。
NNTP 用于新闻的发布、检索和获取。
HTTP 用于在 WWW 上获取网页。
OSI 参考模型 OSI 参考模型是国际标准化组织指定的一个用于计算机或通信系统之间互联的标准体系。
TCP/IP 特点
TCP/IP 协议不依赖于任何特定的计算机硬件或操作系统,提供开放的协议标准。
TCP/IP 并不依赖于特定的网络传输硬件,所以 TCP/IP 协议能够集成各种各样的网络。
统一的网络地址分配方案,使整个 TCP/IP 设备在网中都有唯一的地址。
标准化的高层协议,可以提供多种可靠的服务。
HTTP 协议 开发中,我们经常需要向服务器端发送数据或从服务器端请求特定数据,为了完成数据在客户端和服务器端的传输,我们在传输数据时必须用到 HTTP 协议。
什么是 HTTP 协议? HTTP 协议,即 HyperText Transmission Protocol,超文本传输协议,定义了客户端与服务器端的数据传输规则,让客户端和服务器能够有效地进行数据沟通。
HTTP 的基本性质
HTTP 是简单的
HTTP 是可扩展的 - 通过 HTTP headers 可以轻松对协议进行扩展
HTTP 是无状态,有会话的 - 在同一个连接中,两个执行成功的请求之间是没有关系的
HTTP 请求与响应 HTTP 请求 HTTP 协议规定,一个完整的 HTTP 请求应包含如下内容
请求行 :包含请求方法、请求统一资源标示符和 HTTP 版本号。
请求头 :请求头包含客户端传送给服务器端的附加信息。
Name
Description
Host
目标服务器的网络地址
Accept
告知服务器端客户端能够接收的数据类型,如 ‘text/html’等
Content-Type
请求体中的数据类型,如 ‘Application/Json; charset=UTF-8’等
Accept-Language
客户端的语言环境,如 ‘zh-cn’ 等
Accept_Encoding
客户端支持的数据压缩格式,如 ‘gzip’ 等
User-Agent
客户端的软件环境
Connection : keep-alive
告知服务器这是一个持久连接
Content-Length
请求体的长度
Cookie
记录着用户保存在本地的用户数据
请求体 :发送给服务器端的数据
在使用 POST-Multipart 上传请求中请求体就是上传文件的二进制数据。
在使用 GET 请求时,请求体为空。
在普通的 POST 请求中,请求体就是表单数据。
响应状态行 : 服务器返回给客户端的状态信息,一般包含 HTTP 版本号、状态码和状态码对应的英文名称。
一个典型的状态行如下:
HTTP 响应 基本与 HTTP 请求相同。
HTTP 的版本 HTTP 的主要版本如下
Version
Feature
< HTTP 1.1
不支持持久连接;无请求头和响应头;客户端的前后请求是同步的。
HTTP 1.1
增加请求头和响应头;支持持久连接;客户端的不同请求之间是异步的。
HTTP 2.0
向下兼容 HTTP 1.1,但只用于 https 网址。
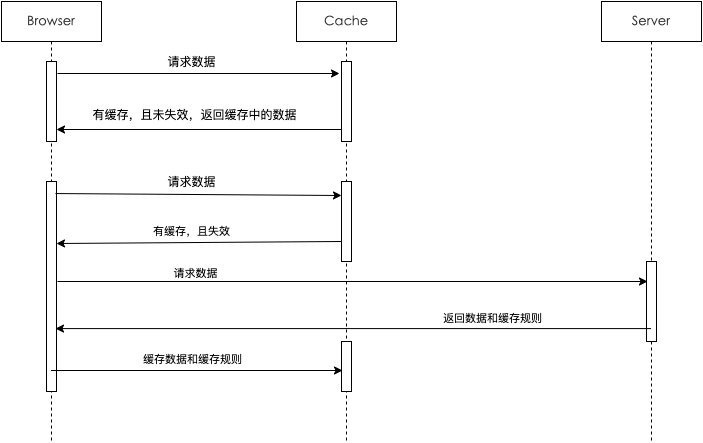
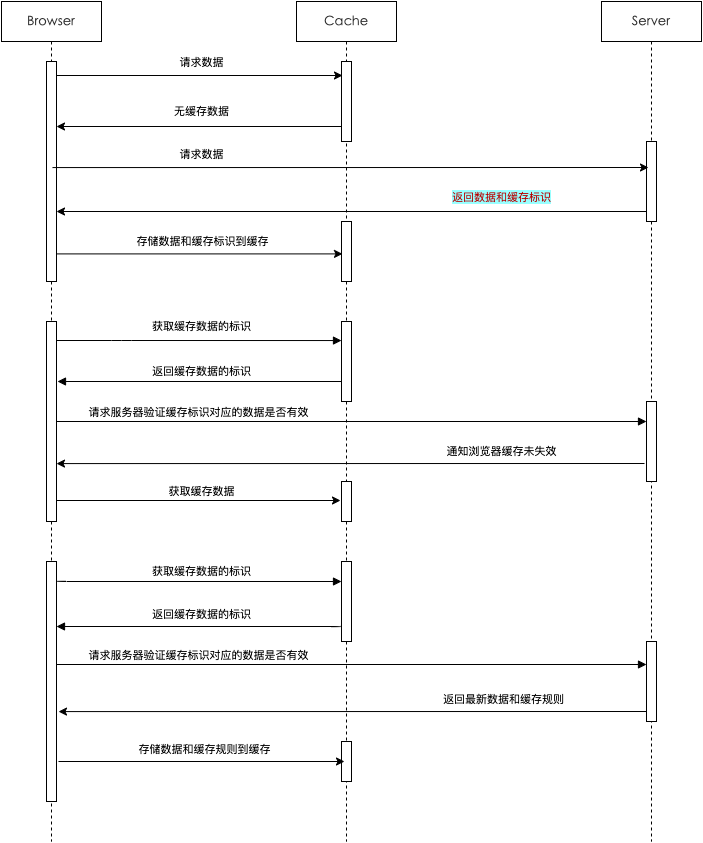
HTTP 缓存 缓存是一种保存资源副本并在下次请求时直接使用该副本的技术。当 web 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的拷贝,而不会去源服务器重新下载。这样带来的好处有:缓解服务器端压力,提升性能(获取资源的耗时更短了)。对于网站来说,缓存是达到高性能的重要组成部分。缓存需要合理配置,因为并不是所有资源都是永久不变的:重要的是对一个资源的缓存应截止到其下一次发生改变(即不能缓存过期的资源)。
缓存操作的目标 虽然 HTTP 缓存不是必须的,但重用缓存的资源通常是必要的。然而常见的 HTTP 缓存智能存储 GET 响应。
缓存控制 Cache-control 头HTTP/1.1 定义的 Cache-Control 头用来区分对缓存机制的支持情况,请求头和响应头都支持这个属性,你可以通过它提供的不同的值来定义缓存策略。
禁止进行缓存
1 2 Canche-Control: no-store, Canche-Control: no-cache, no-store
强制确认缓存
每次有请求发出时,缓存会将次请求发送到服务器,服务器端会验证请求中所描述的缓存是否过期,若未过期,则缓存才使用本地缓存副本
1 Cache-Control: must-revalidate
私有缓存和公共缓存
public 指令表示该响应可以被任何中间人缓存。若指定了 public ,则一些通常不被中间人缓存的页面,将被缓存。
private 则表示该响应是专用于某单个用户的,中间人不能缓存此响应。
缓存过期机制
max-age=<seconds> 指令表示资源能够被缓存的最大时间,这个时间是距离请求发起的时间的秒数。一般用来缓存应用中不会改变的文件,通过手动设置一定的时长以保证缓存有效。
1 Cache-Control: max-age=10000
缓存验证确认
当使用了 must-revalidate 指令,那就意味着缓存在考虑使用一个资源时,必须先验证它的状态,已过期的缓存将不被使用
Pargma 头Pargma 是 HTTP/1.1 标准中定义的一个 header 属性,请求中包含 Pargma 的效果跟在头信息中定义 Cache-Control: no-cache 相同,但是 HTTP 的响应头不支持这个属性,所以它不能完全替代 Cache-Control 头。
新鲜度 在过期时间之前,缓存资源是新鲜的,否则是陈旧的。一个陈旧的资源是不会被直接清除的,当客户端发起一个请求时,检索到已经有一个对应的缓存副本,则会在此次请求上附加一个 If-None-Match 头,然后再发送给服务器,以此来检查此资源是否依然是新鲜的,若返回 304 (Not Modified) ,则表示该副本是新鲜的,否则返回新的资源。
缓存验证 用户点击刷新按钮时会开始缓存验证。如果缓存的响应头信息里含有 Cache-control: must-revalidate 的定义,在浏览的过程中也会触发缓存验证。另外,在浏览器偏好设置里设置 Advanced->Cache 为强制验证缓存也能达到相同的效果。
当缓存的文档过期后,需要进行缓存验证或者重新获取资源。只有在服务器返回强校验器或者弱校验器时才会进行验证。
ETag作为缓存的一种强校验器,ETag 响应头是一个对用户代理不透明的值。对于像浏览器这样的 HTTP UA,不知道 ETag 代表什么,不能预测它的值是多少。如果资源请求的响应头里含有 ETag, 客户端可以在后续的请求的头中带上 If-None-Match 头来验证缓存。
Last-Modified 响应头可以作为一种弱校验器。说它弱是因为它只能精确到一秒。如果响应头里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。
当向服务端发起缓存校验的请求时,服务端会返回 200 ok 表示返回正常的结果或者 304 Not Modified表示浏览器可以使用本地缓存文件。304 的响应头也可以同时更新缓存文档的过期时间。
需要注意的是 If-None-Match 的优先级高于 If-Modified-Since,两者同时存在的话,按照前者进行校验。
带 Vary 头的响应 Vary HTTP 响应头决定了对于后续的请求头,如何判断是请求一个新的资源还会使用缓存的文件。
当缓存服务器收到一个请求,只有当前的请求和原始(缓存)的请求头跟缓存的响应头里的Vary都匹配,才能使用缓存的响应。
HTTP Cookies HTTP Cookie(也叫Web Cookie或浏览器Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。Cookie 使基于无状态的 HTTP 协议记录稳定的状态信息成为了可能。
创建 Cookie 服务器通过在响应头里面添加一个 Set-Cookie 选项,来使浏览器保存下 Cookie,之后对该服务器的每一次请求中都通过 Cookie 请求头部将 Cookie 信息发送给服务器。
Set-Cookie 响应头部和 Cookie 请求头部
服务器使用 Set-Cookie 响应头部向用户代理发送 Cookie 信息
1 Set-Cookie: <name > =<value >
保存 Cookie 信息后,对该服务器发起的每一次新请求,浏览器都会将保存的 Cookie 信息通过 Cookeie 请求头再发送给服务器。
会话期 Cookie
会话期 Cookie 是最简单的 Cookie:浏览器关闭后它会被自动删除,即它仅在会话期内有效。
会话期 Cookie 不需要指定过期时间或者有效期
持久性 Cookie
持久性 Cookie 指定了特定的过期时间或有效期,不会随着浏览器的关闭而被删除。
1 2 Set-Cookie : id=asfwa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;
设定的过期时间只和客户端有关,而不是服务端。
Cookie 的 Secure 和 HttpOnly 标记
标记为 Secure 的 Cookie 只应通过被 HTTPS 协议加密过的请求发送给服务器,但由于 Cookie 固有的不安全性,敏感信息不应该通过 Cookie 传输。
为避免跨域脚本攻击,通过 JavaScript 的 Document.cookie API 无法访问带有 HttpOnly 标记的 Cookie,它们只应发送给服务器。
Cookie 的作用域
通过 Domain 和 Path 标识可以定义 Cookie 的作用域:即 Cookie 应该发送给哪些 URL。
Domain 指定哪些主机可以接受 Cookie,如果不指定,则默认为当前文档的主机,且不包含子域名。如果指定了,则会包含子域名。
Path 指定主机下的哪些路径可以接受 Cookie,以字符 %x2F (即 /) 作为路径分隔符,子路径也会被匹配。
SameSite Cookies
SameSite Cookie 允许服务器要求某个 Cookie 在跨站请求时不会被发送,从而可以组织跨站请求伪造攻击。
JavaScript 通过 document.cookies 访问 Cookie
通过 Document.cookie 属性可创建新的 Cookie,也可以通过该属性访问非 HttpOnly 标记的 Cookie。
Cookie 安全 当机器处于不安全环境时,切记不能通过 Cookie 存储传输敏感信息。
追踪和隐私
第三方 Cookie
每个 Cookie 都会有与之关联的域(Domain),如果 Cookie 的域和页面的域相同,那么我们称这个 Cookie 为第一方 Cookie ,如果 Cookie 的域和页面的域不同,则称之为第三方Cookie。一个页面包含图片或存放在其他域上的资源(如图片广告)时,第一方的 Cookie 也只会发送给设置它们的服务器。通过第三方组件发送的第三方 Cookie 主要用于广告和网络追踪。
禁止追踪 Do-Not-Track
虽然并没有法律或者技术手段强制要求使用DNTDNT
欧盟 Cookie 指令
僵尸 Cookie 和删不掉的 Cookie
HTTP 访问控制 跨域资源共享(CORS)是一种使用额外的 HTTP 头来使运行在一个 origin 上的 web 应用被准许访问来自不同源服务器上的指定的资源的机制,即当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,就会发起一个跨域 HTTP请求。
跨域资源共享标准新增了一组 HTTP 首部字段,允许服务器声明哪些源站通过浏览器有权限访问哪些资源。对那些可能对服务器数据产生副作用的 HTTP 请求方法,浏览器必须首先使用 OPTIONS 方法发起一个预检请求(Preflight Request),从而获知服务端是否允许该跨域请求。服务端确认允许后,才发起实际的 HTTP 请求。
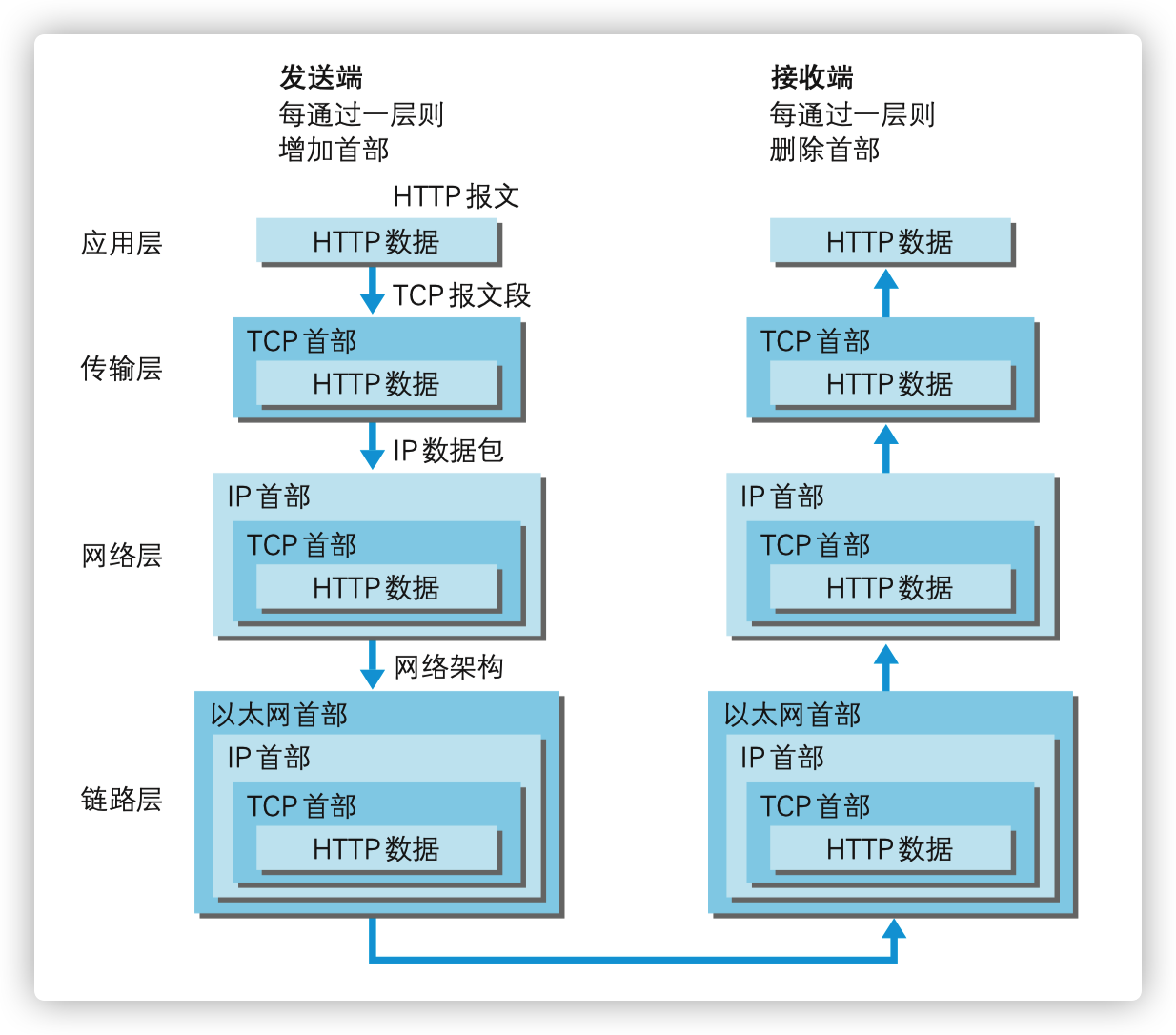
HTTP 消息 HTTP 消息是客户端和服务器之间交换数据的方式。它们分为两种类型:由客户端发送的用来在服务器上触发动作的消息和从服务器得到的回应。
HTTP 消息由跨越多行的用 ASCII 编码的文本信息组成。在 HTTP/1.1 和更早期的版本的协议中,消息通过连接明文发送。在 HTTP/2 中,为了优化和性能提升,人类可读的消息被分割成 HTTP 帧。
HTTP Request 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 GET /img/me.png HTTP/1.1 GET http: User-Agent Accept Accept-Language Accept-Encoding Connection Content-Type Content-Length
HTTP Response 1 2 3 4 5 6 7 8 HTTP/1.1 404 Not Found
HTTP/2 帧 HTTP/1.1 的消息在性能上有着一系列的缺点:
Header 不像 body,它不会被压缩
两个报文之间的 header 通常非常相似,但它们仍然在连接中重复传输
无法复用。当在同一个服务器打开几个连接时:TCP 热连接比冷连接更加有效
所以在 HTTP/2 中,消息被分割成嵌入到流中的帧。Headers 和 Body 的帧是分开的,这使得 Headers 帧也可以被压缩。多个流可以被组合在一起,这是一种称为多路复用的技术,它使得 TCP 连接下的传输更有效率。
HTTP 会话 在类似 HTTP 的客户端-服务器协议中,会话由三个部分组成:
客户端建立一个 TCP 连接
客户端发送请求,等待回应
服务器处理请求,做出回应
从 HTTP/1.1 起,连接在完成第三部后不再被关闭,客户端被允许发起新的请求,这意味着第二和第三部可以重复进行多次。
客户端-服务器协议中,在 HTTP 中打开一个连接,意味着在底层传输层初始化连接。使用 TCP 时,HTTP 服务器默认的端口号是 80。
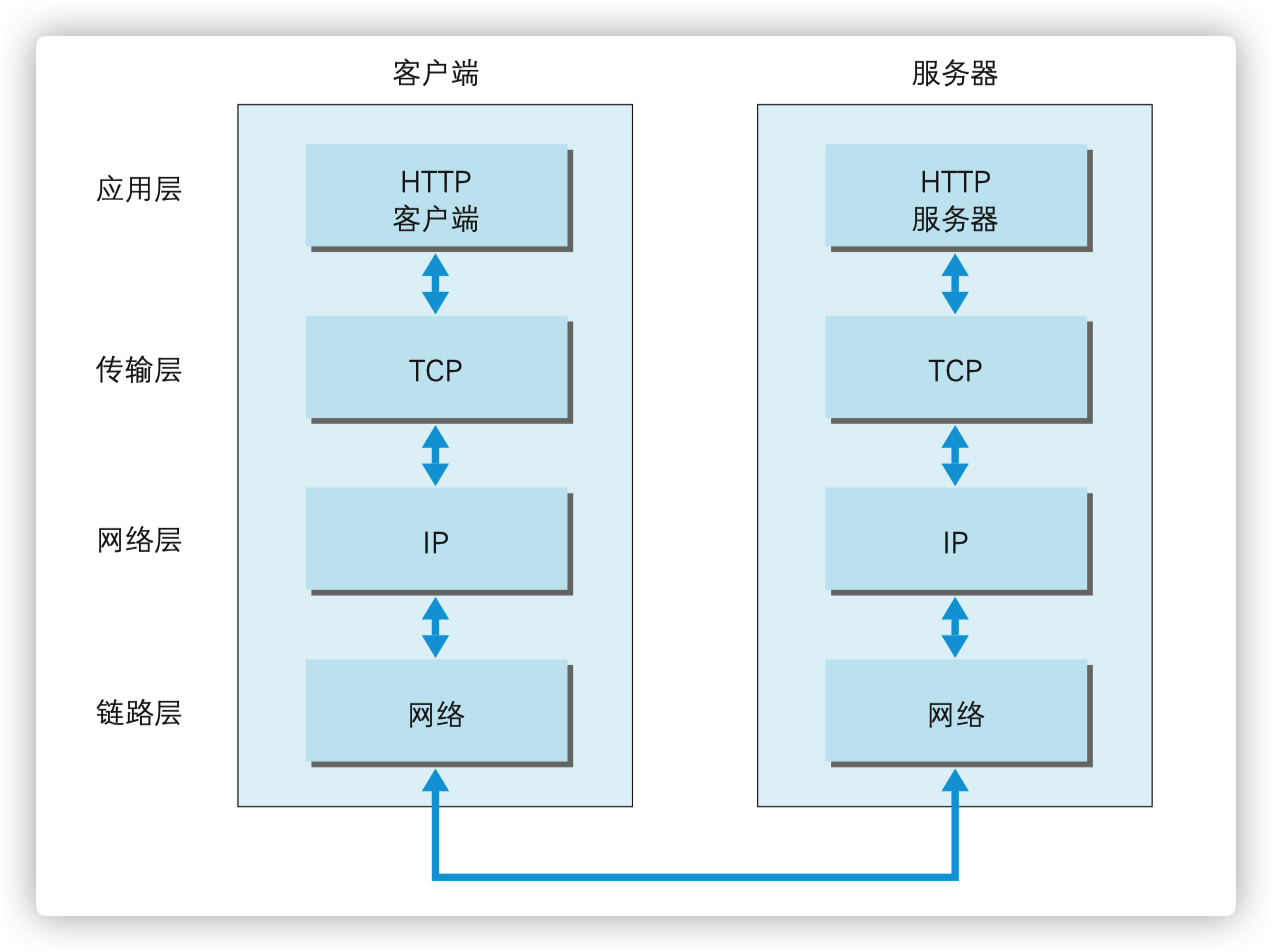
HTTP 、Scoket 和 TCP 的区别 HTTP 是应用层的协议,TCP 是传输层的协议,而 Socket 是从传输层抽象的一个抽象层,本质是接口。
TCP 连接与 HTTP 连接的区别
HTTP 是基于 TCP的,客户端向服务器端发送一个 HTTP 请求时,第一步就是要建立与服务端的 TCP 连接。
TCP 连接与 Socket 连接的区别
Socket 层只是在 TCP/UDP 传输层上做的一个抽象接口层。
基于 TCP 协议的 Socket 连接同样需要通过三次握手建立连接,是可靠的。
基于 UDP 协议的 Socket 连接不需要建立连接的过程,不管对方能不能收到都会发送过去,是不可靠的。
HTTP 连接与 Socket 连接的区别
HTTP 是短连接,基于 TCP 协议的 Socket 连接是长连接。尽管 HTTP 1.1 开始支持持久连接,但仍无法保证始终连接。
而基于 TCP 协议的 Socket 连接一旦建立成功,除非一方主动断开,否则连接状态一直保持。
HTTP 连接,服务器无法主动发送消息,而 Socket 连接,双发请求的发送没有先后限制。
HTTP 采用 ‘请求-响应’ 机制,在客户端没有发送请求给服务端时,服务端无法推送消息给客服端。
Socket 连接双方类似于 P2P 的关系,可以随时互相发送消息。