JavaScript 正则表达式
JavaScript 正则表达式
什么是正则表达式?
正则表达式是一些用来匹配和处理文本的字符串。
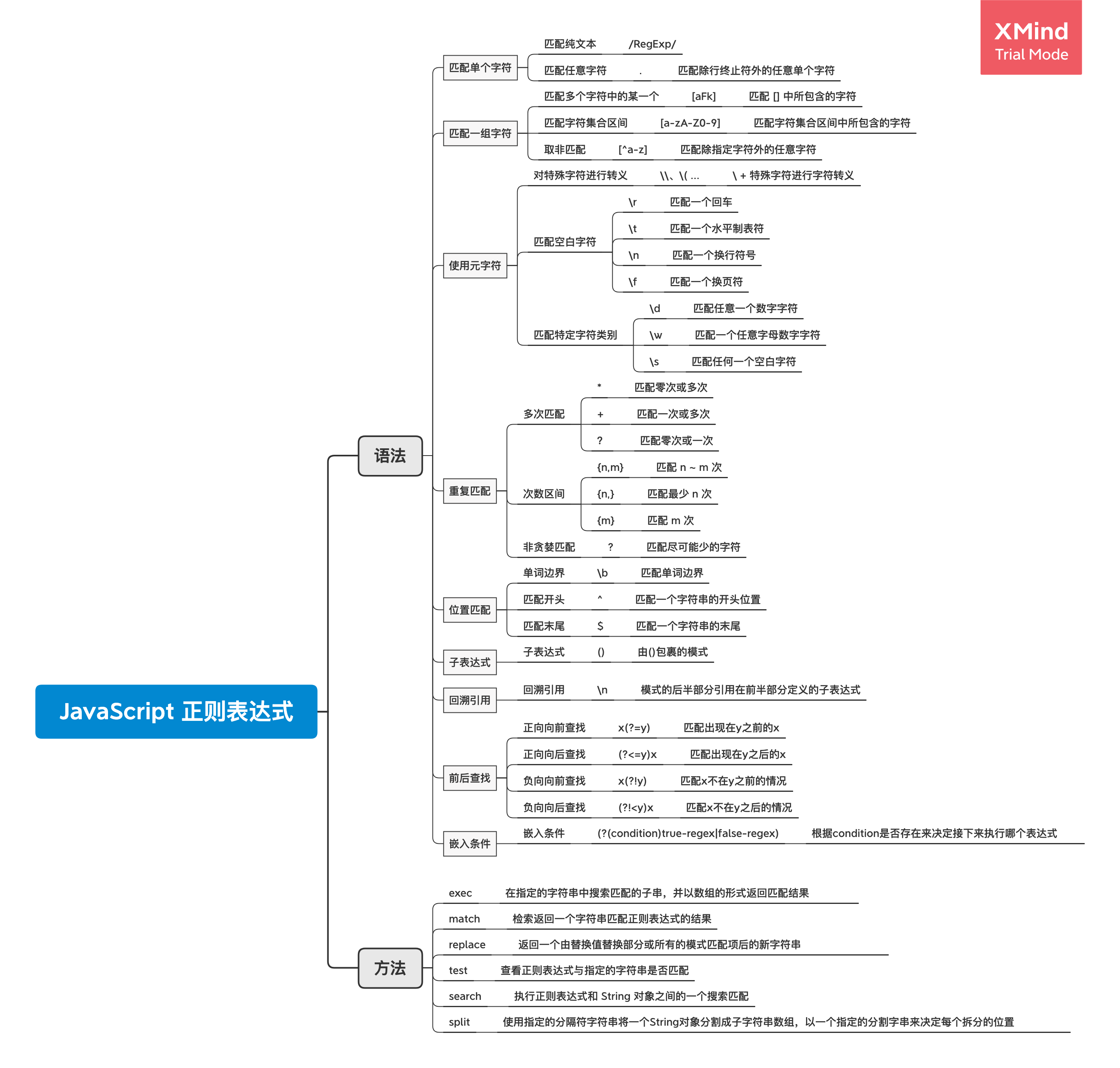
语法
可以使用字面量、构造器和工厂标记来创建正则表达式
1 | /partern/flags |
其中 flags
g全局匹配i不区分大小写m多行匹配uUnicode 字符匹配
正则表达式中的特殊字符
字符类
.匹配除行终止符(\n,\r,\u2028 or \u2029)之外的任何单个字符,若在字符集中则仅仅只匹配.\d匹配任何一个数字字符,相当于[0-9]\D匹配任何一个非数字字符,相当于[^0-9]\w匹配任何一个字母数字字符,包括下划线,相当于[A-Za-z0-9_]\W匹配任何一个非字母数字字符或非下划线字符,相当于[^A-Za-z0-9_]\s匹配任何单个空格字符,相当于[\f\n\r\t\v\u00a0\u1680\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]\S匹配除了空格外的单个字符,相当于[^ \f\n\r\t\v\u00a0\u1680\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]\t匹配一个横向制表符\r匹配一个回车\n匹配一个换行符\v匹配一个垂直制表符\f匹配一个换页符[\b]匹配一个删除符\0匹配 NUL 字符\cX匹配控制字符
字符集
[-a-z-]匹配方括号中字符中的任何一个,可以使用连字符-来指定字符范围,但如果连字符是方括号中的第一个或最后一个字符,则作为普通字符包含在字符集中。也可以在字符集中包含字符类。[^-A-Z-]匹配除括号中包含的内容外的任何内容
可选字符
x|y匹配 x 或 y 中的一个
边界
^匹配开头,如果设置了多行匹配标记,则在换行符后立即匹配$匹配结尾\b匹配单词边界,实际上它匹配的是一个能够构成单词的字符(\w)和一个不能构成单词的字符(\W)之间的位置\B匹配非单词边界
分组和反向引用
(x)匹配 x 并记录匹配结果,称为捕获分组\n引用之前的第 n 个 表达式(?:x)匹配 x 但不记录匹配结果,称为非捕获分组
量词
x*匹配 x 0次或更多次x+匹配 x 1次或更多次x?匹配 x 0次或1次x{n}匹配 x n次x{n,}匹配 x 至少n次x{n,m}匹配 x 至少n次至多m次?非贪婪匹配,在量词后加上?表示量词的非贪婪模式,匹配尽可能少的字符
回溯引用
x(?=y)前向查找,仅当x后跟y时,才匹配x
(?<=y)x后向查找,仅当x前面有y时,才匹配x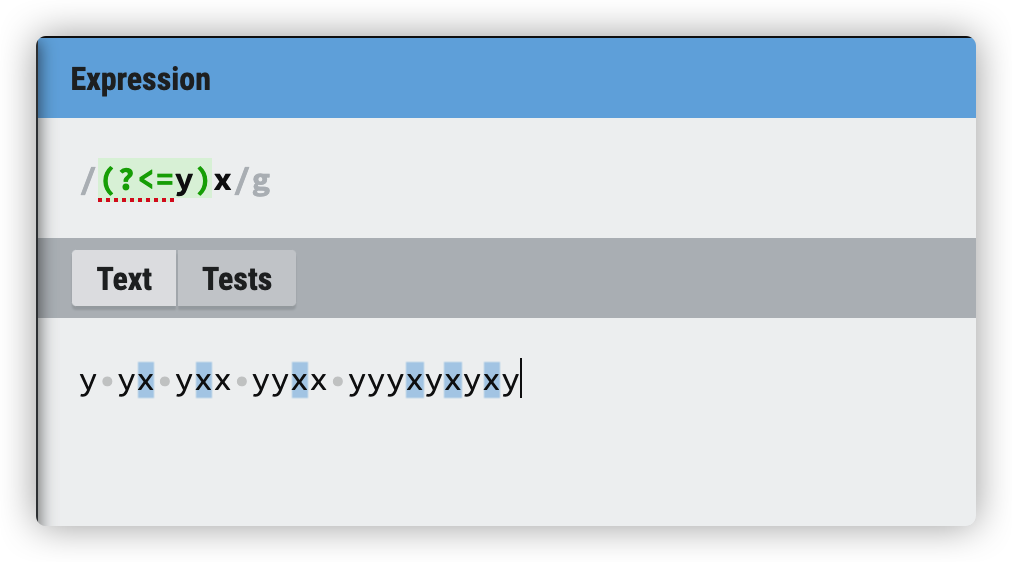
常用的方法
exec()在指定的字符串上执行匹配搜索,返回结果数组或
null1
2
3
4
5
6
7
8const str = "My ip address is 255.198.99.101 and your ip address 199.123.44.88";
const reg = /\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}/g;
// Found 255.198.99.101, from index 17, last match from index 31
// Found 199.123.44.88, from index 52, last match from index 65
while((res = reg.exec(str)) !== null) {
console.log(`Found ${res[0]}, from index ${res['index']}, last match from index ${reg.lastIndex}`);
}test()在指定的字符串和一个正则表达式之间执行匹配搜索,返回
true或falsematch()对给定的字符串进行匹配并返回匹配结果
1
2
3
4
5const str = "My ip address is 255.198.99.101 and your ip address 199.123.44.88";
const reg = /\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}/g;
// [ '255.198.99.101', '199.123.44.88' ]
console.log(str.match(reg));replace()使用给定的字符串替换匹配到的结果
search()在给定的字符串中搜索匹配,并返回首次匹配结果的索引
split()通过将字符串分隔为子字符串,将字符串拆分为数组。
常用正则表达式
匹配中文字符
1
/^[\u4e00-\u9fa5]{0,}$/
匹配双字节字符
1
/[^\x00-\xff]/
匹配千分位
1
/\B(?=(\b{3})+(?!\d))/
匹配两位小数
1
/^([1-9][0-9]*)(\.[0-9]{2})?$/
匹配中国固定电话号码
最开始的一位一定是 0,接着是 2,3,4位数字组成的区号,然后是7位或8位的电话号码,其中首位不为1
1
/\(?0[1-9]\d{1,3}\)?[ -]?[2-9]\d{2,3}[ -]?\d{4}/
匹配统一社会信用代码
统一社会信用代码由18位数字或者大写字母组成,但是字母不包括 I、O、Z、S、V
一共由五部分组成:
第一部分:登记管理部门代码1位 (数字或大写英文字母)
第二部分:机构类别代码1位 (数字或大写英文字母)
第三部分:登记管理机关行政区划码6位 (数字)
第四部分:主体标识码(组织机构代码)9位 (数字或大写英文字母)
第五部分:校验码1位 (数字或大写英文字母)
1
/[0-9A-HJ-NPQRTUWXY]{2}\d{6}[0-9A-HJ-NPQRTUWXY]{10}/
目前还有老的工商注册代码,也就是15位的社会信用代码,正则表达式如下:(弱校验)
1
/[1-9]\d{15}/
同时支持18位和15位社会信用代码
1
/^([0-9A-HJ-NPQRTUWXY]{2}\d{6}[0-9A-HJ-NPQRTUWXY]{10}|[1-9]\d{14})$/
中国邮政编码
前两位代表省、市、自治区,第三位代表邮区,第四位代表县、市,最后两位代表投递邮局,其中第二位不为 8。
1
/\d[0-7|9][0-9]{4}/
中国身份证号码
前六位是户口所在地编码,其中第一位是 1~8,此后是出生年月日,出生年份只能是 18、19、20,而且是可选的,最后一位校验位是数字或 x
1
/[1-8]\d{5}((18)|(19)|(20))?\d{2}(0[1-9]|1[0-2])((0|1|2)[1-9]|3[0-1])\d{3}[\dx]?/
JavaScript 中的特殊字符
| Unicode | 转义序列 | 含义 | 类别 |
|---|---|---|---|
| \u0008 | \b | Backspace | |
| \u0009 | \t | Tab | 空白 |
| \u000A | \n | 换行符 | 行终止符 |
| \u000B | \v | 垂直制表符 | 空白 |
| \u000C | \f | 换页 | 空白 |
| \u000D | \r | 回车 | 行终止符 |
| \u0022 | " | 双引号 | |
| \u0027 | ' | 单引号 | |
| \u005C | \ \ | 反斜杠 | |
| \u00A0 | 不间断空格 | 空白 | |
| \u0028 | 行分隔符 | 行终止符 | |
| \u0029 | 段落分割符 | 行终止符 | |
| \uFEFF | 字节顺序标记 | 空白 |
JavaScript 正则表达式
https://cocoalei.github.io/blogs/2018/09/02/JavaScript 正则表达式/